在人工智能对话系统的开发中,意图识别(Intent Recognition)是一项核心技术,它直接影响着用户体验和系统效能。本文将全面解析意图识别在大模型对话Agent中的应用,从基础概念到实际应用案例,帮助开发者构建更智能的对话系统。
一、意图识别的重要性
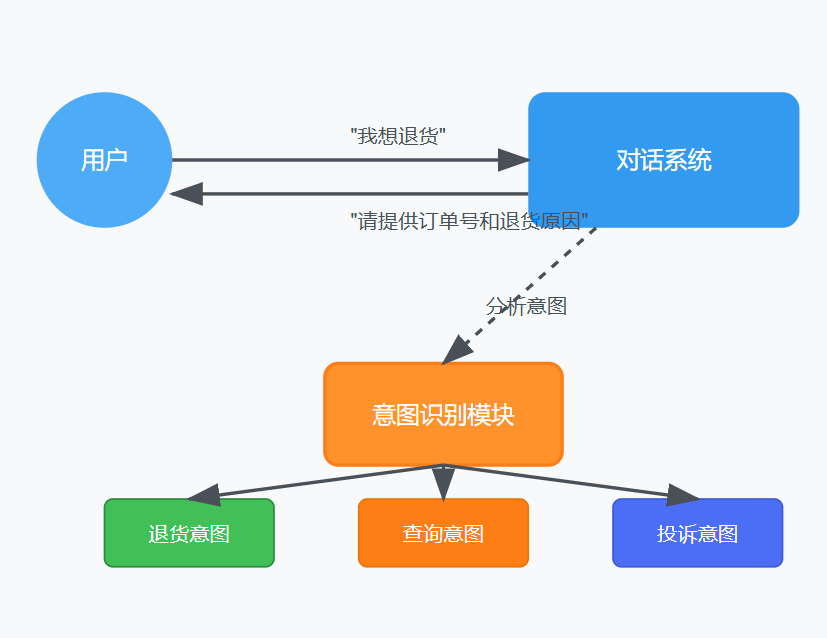
意图识别是对话系统的基础组件,其价值主要体现在以下方面:
1. 有效引导对话流程
意图识别能够帮助系统准确理解用户的需求,进而合理规划对话路径。例如,当系统识别用户想要查询订单状态时,会引导用户提供必要信息(如订单号),确保对话朝着满足用户需求的方向发展。
用户:我想知道我的包裹到哪里了
系统:[识别意图:查询物流] 您好,为了帮您查询包裹状态,请提供您的订单号或手机号。
2. 提高对话效率
准确的意图识别可以减少对话轮次,避免因理解偏差导致的沟通困难。
用户:我收到的商品有问题,想退货
系统:[识别意图:退货] 了解了,为处理您的退货请求,我需要确认几个信息:
1. 您的订单号是什么?
2. 商品有什么具体问题?
3. 您希望退款还是换货?
若系统错误识别为"查询商品信息"的意图,用户则需要额外解释,增加对话轮次。
3. 增强用户体验
当系统能精准捕捉用户意图时,用户会感到被理解和重视,提升满意度。反之,频繁的误解会导致用户沮丧,甚至放弃使用。
二、意图识别的技术挑战
1. 规模与复杂性挑战
当前业界面临的主要挑战是,较小规模的模型在处理长对话时表现欠佳:
- 当对话超过3轮且每轮内容较多时,模型容易混淆上下文关系
- 对话长度增加,语义理解负担加重,回复质量明显下降
- 多意图交织的复杂对话场景下,准确率显著降低
2. 解决思路
思路1:截断历史对话
最简单的方法是保留最近几轮对话,舍弃更早的内容。这种方法虽然直接,但会导致上下文连贯性断裂,影响对话体验。
[截断前]
用户:我想买一台手机
系统:有什么具体需求吗?
用户:预算5000以内,拍照要好
系统:推荐您考虑以下几款...
用户:这款电池续航如何?
[截断后] - 仅保留最后一轮
用户:这款电池续航如何?
系统:[失去上下文,无法确定是哪款手机]
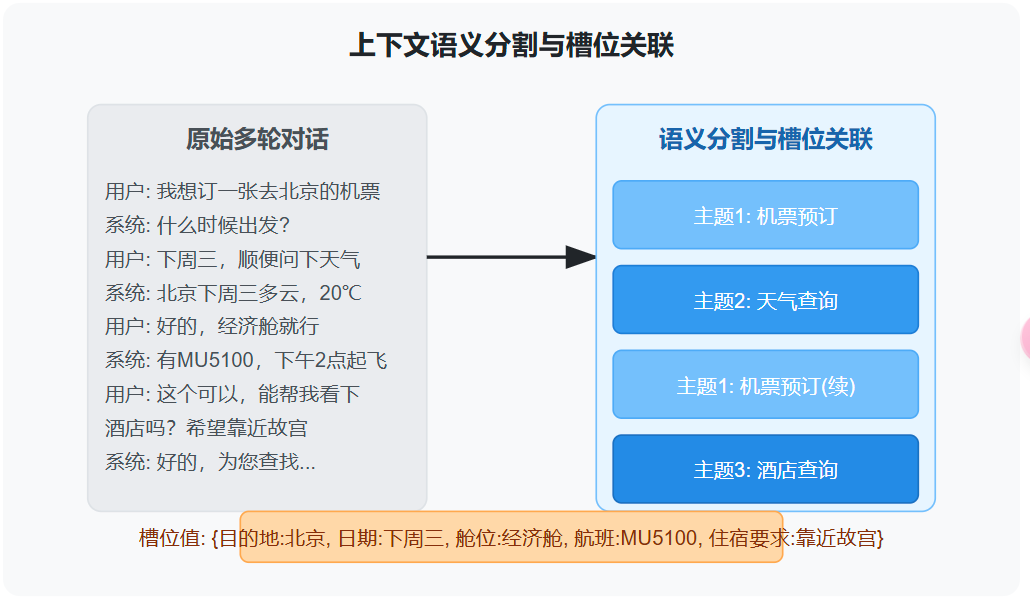
思路2:上下文语义分割和槽位关联
这种方法通过将对话分解为不同的语义单元,并建立关联关系,保留关键信息:
- 上下文语义分割:识别对话中的主题段落,保留关键信息
- 槽位关联:跟踪对话中出现的实体信息(如产品名称、数量等),便于后续使用
思路3:基于多路多轮数据的微调
针对大模型进行特定任务的微调,提升模型在多轮对话中的表现:
- 构建多轮对话数据集,覆盖不同场景下的意图转换模式
- 通过微调使模型更好地学习上下文依赖关系
- 增强模型在长对话中保持一致性的能力
三、单轮意图识别
单轮意图识别是指仅基于用户的单一输入判断其意图,不考虑历史对话内容。
1. 实现方案
(1) 基于规则的方法
使用预定义的规则和模式匹配来识别意图。
规则示例
rules = {
"天气": ["天气", "温度", "下雨", "晴天"],
"订票": ["机票", "订票", "航班", "飞机"],
"退款": ["退款", "退钱", "退回", "返还"]
}
def rulebasedintent(text):
for intent, keywords in rules.items():
for keyword in keywords:
if keyword in text:
return intent
return "未知意图"
优点:实现简单,可解释性强 缺点:缺乏灵活性,难以覆盖表达的多样性
(2) 向量检索方法
将用户输入与预先准备的意图示例转换为向量,通过计算相似度确定最接近的意图。
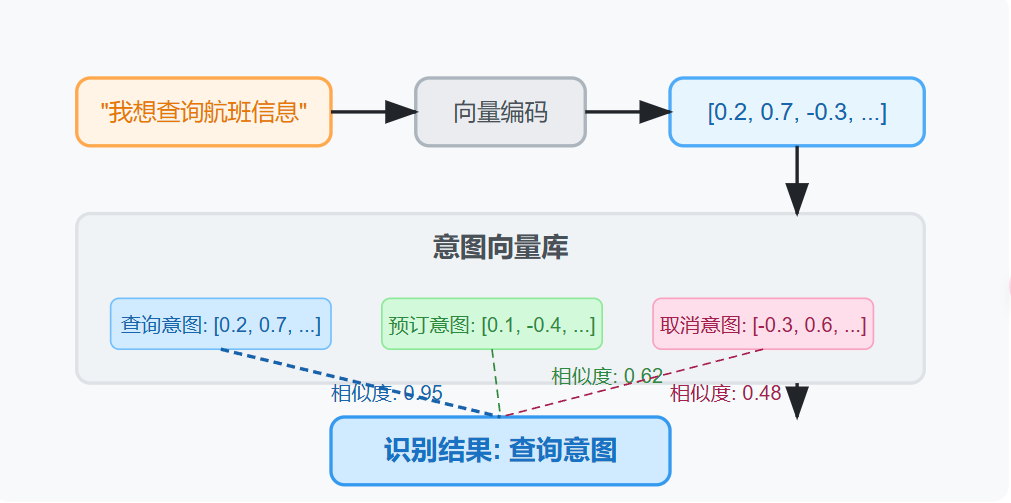
image-20250321180902305
from sentencetransformers import SentenceTransformer
from sklearn.metrics.pairwise import cosinesimilarity
加载预训练模型
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
意图示例
intent_examples = {
"查询航班": ["查询航班信息", "航班什么时候到", "有没有去北京的航班"],
"预订机票": ["我想订机票", "帮我买一张机票", "预订明天的机票"],
"退票": ["我要退票", "如何取消订单", "退款流程是什么"]
}
计算意图向量
intentvectors = {}
for intent, examples in intentexamples.items():
intentvectors[intent] = model.encode(examples).mean(axis=0)
def vectorbasedintent(query):
# 编码用户查询
queryvector = model.encode(query)
# 计算相似度
similarities = {}
for intent, vector in intentvectors.items():
similarity = cosinesimilarity([query_vector], [vector])[0][0]
similarities[intent] = similarity
# 返回最相似的意图
return max(similarities.items(), key=lambda x: x[1])[0]
优点:可以捕捉语义相似性,不局限于关键词匹配 缺点:依赖于示例的质量和数量,需要维护向量库
(3) 基于深度学习的方法
使用神经网络直接从文本中学习意图特征,常见的模型包括CNN、RNN和Transformer架构。
import tensorflow as tf
from tensorflow.keras.layers import Dense, Embedding, LSTM
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
假设已有标注数据集
texts = ["查询明天的天气", "帮我订一张机票", ...]
labels = ["天气查询", "订票", ...]
文本预处理
tokenizer = Tokenizer()
tokenizer.fitontexts(texts)
sequences = tokenizer.textstosequences(texts)
X = pad_sequences(sequences, maxlen=50)
标签编码
labelencoder = LabelEncoder()
y = labelencoder.fittransform(labels)
y = tf.keras.utils.tocategorical(y)
构建模型
model = Sequential([
Embedding(len(tokenizer.wordindex) + 1, 128, inputlength=50),
LSTM(64),
Dense(len(set(labels)), activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
训练模型
model.fit(X, y, epochs=10, batchsize=32, validationsplit=0.2)
优点:可以自动学习特征,表现更好 缺点:需要大量标注数据,训练和部署成本高
(4) 基于大模型的方法
利用预训练大模型的强大语义理解能力来识别意图。
import openai
def llmintentrecognition(text):
prompt = f"""
请识别以下文本的用户意图,从以下选项中选择最合适的一个:
- 天气查询
- 机票预订
- 酒店预订
- 餐厅推荐
- 退款/取消
用户输入: "{text}"
意图:
"""
response = openai.Completion.create(
model="gpt-3.5-turbo",
prompt=prompt,
temperature=0,
max_tokens=10
)
return response.choices[0].text.strip()
优点:语义理解能力强,部署简单,可处理复杂表述 缺点:响应延迟较高,成本较高,黑盒特性不便于调试
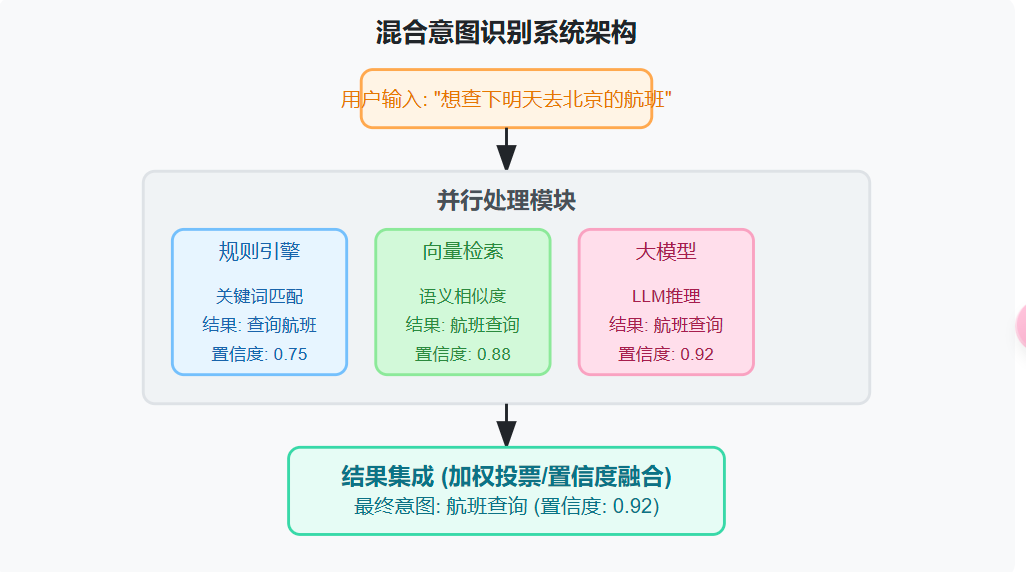
(5) 混合方案
结合多种方法的优势,构建更强大的意图识别系统。
四、多轮意图识别
多轮意图识别比单轮更为复杂,需要考虑对话历史和上下文信息。它处理的是连续多轮对话中意图的变化和延续。
1. 多轮对话的特点
与单轮对话相比,多轮对话具有以下特点:
- 上下文依赖性:后续轮次的意图理解依赖于前面轮次的内容
- 意图转换:用户可能在对话过程中切换话题或改变意图
- 省略现象:用户可能省略已在上文中提及的信息
- 指代现象:用户使用代词指代前面提到的实体
2. 实现方法
(1) 上下文窗口法
保留最近N轮对话作为上下文,综合考虑整个窗口内的信息。
def contextwindowintent(currentutterance, history, windowsize=3):
# 提取最近的N轮对话
recentcontext = history[-windowsize:] if len(history) > window_size else history
# 构建上下文窗口
context = "\n".join(recentcontext + [currentutterance])
# 使用LLM进行意图识别
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "识别用户在对话中的当前意图"},
{"role": "user", "content": f"对话历史:\n{context}\n\n识别最后一句的意图"}
],
temperature=0
)
return response.choices[0].message["content"]
(2) 对话状态追踪法
维护对话状态,跟踪意图变化和槽位填充情况。
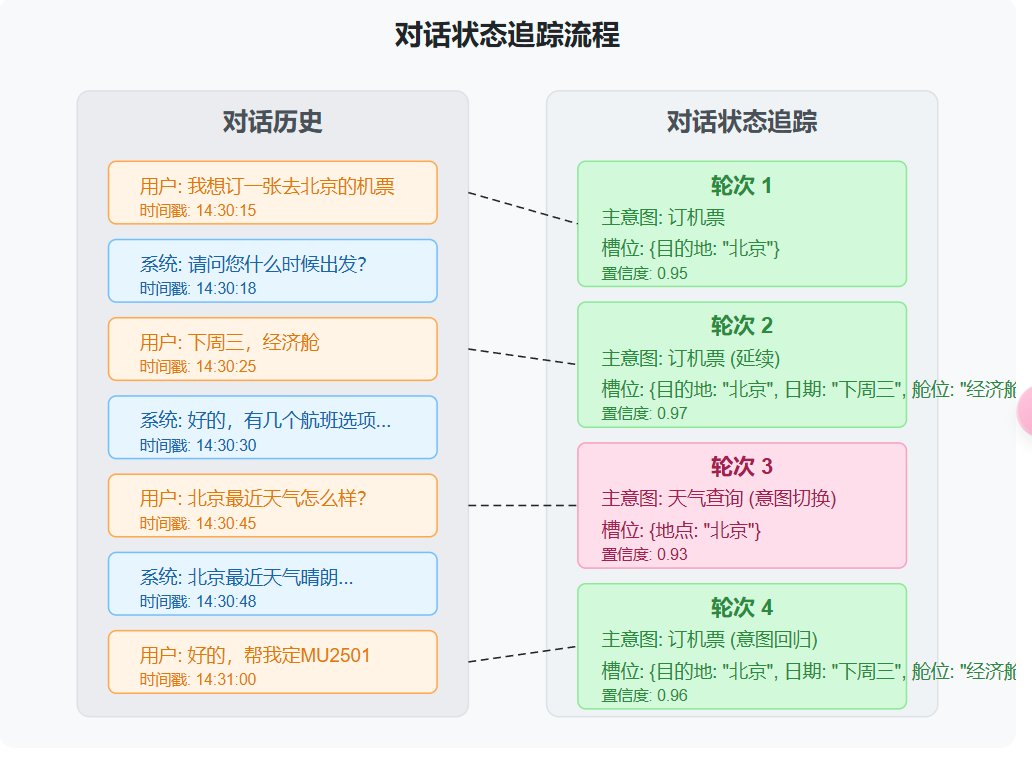
class DialogueStateTracker:
def init(self):
self.currentintent = None
self.intenthistory = []
self.slots = {}
self.confidence = 0.0
def updatestate(self, utterance, history):
# 使用当前和历史信息更新状态
previousintent = self.current_intent
# 识别当前意图
newintent, confidence = self.recognize_intent(utterance, history)
# 提取槽位信息
newslots = self.extract_slots(utterance, history)
# 判断是否是新意图还是延续
if previousintent and self.isintentcontinuation(previousintent, newintent, utterance):
# 延续当前意图,合并槽位
self.slots.update(newslots)
self.confidence = 0.7 self.confidence + 0.3 confidence
else:
# 新意图
self.currentintent = newintent
self.intenthistory.append(newintent)
self.slots = newslots
self.confidence = confidence
return {
"intent": self.currentintent,
"slots": self.slots,
"confidence": self.confidence,
"isswitch": previousintent != self.currentintent
}
(3) 多轮对话意图识别的大模型方法
利用大模型的强大上下文理解能力,直接处理复杂多轮对话。
def llmmultiturnintent(currentutterance, history):
# 构建完整对话上下文
messages = [
{"role": "system", "content": """
您是一个对话分析专家。请分析以下多轮对话,并识别最后一句话的意图。
还要判断这个意图是新的还是延续之前的意图。
同时提取所有相关的槽位信息。
"""}
]
# 添加对话历史
for i, utterance in enumerate(history):
role = "user" if i % 2 == 0 else "assistant"
messages.append({"role": role, "content": utterance})
# 添加当前用户输入
messages.append({"role": "user", "content": current_utterance})
# 添加分析请求
messages.append({"role": "system", "content": "请分析最后一句话的意图和槽位,格式为JSON"})
# 调用API
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0,
responseformat={"type": "jsonobject"}
)
# 解析结果
result = json.loads(response.choices[0].message["content"])
return result
3. 多轮意图识别的应用实例
让我们以一个酒店预订对话为例,展示多轮意图识别的应用: